Graph-structured data is ubiquitous. If you have recently used any of the following technologies --- Facebook, Twitter, Bitcoin, LinkedIn, Google Knowledge Graph, Wolphram Alpha --- you have directly or indirectly created, manipulated, and queried graph-structured data. In fact, Snowden tells us that just about everything we do is tracked in online graph structured databases. We work with graphs in all shapes and sizes, from small data structures that store a family tree to huge social networks.
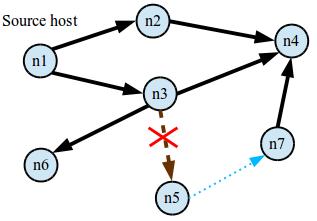
A reachability request on a changing graph.
A common trait of these graphs is that they are constantly changing. And it is a challenge to ensure that queries return a consistent view of the graph as the graph is being modified underneath. If the graph store is not equipped specifically to handle these changes, queries over the graph might return nonsensical results. For example, imagine a graph store used to implement a network controller that stores the network topology shown on the right. Say, we're a cloud provider and our SLA requires us to ensure that certain highly sensitive data is not exposed to some nodes in the network. Yet when the network is undergoing churn, it is possible for a query to return a path through the network that did not exist at any instant in time. For instance, if the link (n3,n5) fails, and subsequently the link (n5,n7) goes online, a traversal starting from host n1 to host n7 may erroneously conclude that n7 is reachable from n1, even though no such path ever existed. This is because typical graph stores are not transactional and expose partial writes to their clients.
Ideally, we'd like all updates to the graph to happen transactionally, and we'd like every query to operate on a consistent snapshot of the graph. And of course, the graph needs to be sharded across multiple hosts to be able to scale. And it needs to be fault-tolerant to address failures of the distributed components. And it should be possible to take a consistent backup of the graph data across a cluster. Most of all, it should be fast.
Weaver is a new graph-store we developed to address these challenges. At its core, Weaver is a distributed graph store that shards the graph over multiple servers.
Weaver has a rich, node-oriented query model, similar to GraphLab. Every node and edge in the graph can have associated with it arbitrary attributes. You can then perform queries that depend on these attributes, such as "give me all the nodes reachable from this user following all the friendship relations" or "starting at this Bitcoin address, perform forward taint analysis" or whatever else. If you can express it in terms of nodes and edges, it can be expressed as a Weaver node program.
Weaver enables transactions over large graphs like this one.
Weaver is transactional. Updates to multiple vertices and edges happen either all at once or not at all. Concurrent updates are serialized into a coherent timeline.
Weaver can tolerate up to a user-specified number of faults while remaining online. And it can take lightning-fast backups that are consistent across the data center.
Weaver scales as you add more nodes. It dynamically repartitions and relocates the graph across servers to take advantage of locality.
And finally, Weaver is fast. It is 12X faster than Titan on social network workloads and over 4X faster than GraphLab on traversal-oriented workloads.
Weaver is currently in alpha. So it's not quite ready for prime time. And it has some shortcomings; for instance, while it's much faster than GraphLab on traversal-oriented queries, it is slower when it comes to iterative global graph computations. If you are computing PageRank, you should do that on GraphLab.
Regardless, we would love to get early feedback from the community, and are releasing the code to hear your comments.
The first step is to install Weaver. You can use the pre-built packages on Ubuntu 14.04 LTS, you can build it from source, or you can just get the Docker image.
The next step is to setup a Weaver cluster, which is fairly straightforward. It involves deploying a few components, but there is a convenient startup script that helps get it started.
The Weaver client provides a familiar transactional API for graph update operations. Application enclose graph operations on predefined vertices and edges in a begin_tx-end_tx block. The following code shows how to create a vertex with handle 'ayush':
cl.begin_tx()
cl.create_node('ayush')
cl.end_tx()A graph with one vertex isn't a lot of fun. So let's add a few more, again in a single all-or-nothing transaction:
cl.begin_tx()
cl.create_node('egs')
for i in range(10):
cl.create_node(str(i))
cl.end_tx()The next step is to create edges between vertices. If the caller does not specify a node or edge handle in Weaver, then the Weaver client automatically creates a unique handle.
cl.begin_tx()
follow_edge = cl.create_edge('ayush', 'egs') # weaver creates a unique handle
cl.end_tx()Vertices and edges may have metadata associated with them, which can be manipulated and read in subsequent queries.
cl.begin_tx()
cl.set_node_property(node='ayush', key='type', value='person')
cl.set_node_property(node='egs', key='type', value='person')
for i in range(10):
cl.set_node_property(node=str(i), key='type', value='person')
cl.set_edge_property(node='ayush', edge=follow_edge, key='type', value='follows')
cl.end_tx()Let's make the people we created randomly be-friend each other in this tiny community we created.
cl.begin_tx()
nodes = [str(i) for i in range(10)] + ['ayush', 'egs']
for i in range(10):
possible_nbrs = [n for n in nodes if n != nodes[i]]
for j in range(4):
nbr = random.choice(possible_nbrs)
possible_nbrs.remove(nbr)
follows = cl.create_edge(nodes[i], nbr)
cl.set_edge_property(node=nodes[i], edge=follows, key='type', value='follows')
cl.end_tx()Now that we've created a graph, we can ask questions about it using Weaver node programs. Remember, a node program executes as a single transaction in spite of concurrent updates to the graph. So you can issue such queries even while the graph is being modified. In the following query, we obtain a list of friends-of-friends of node 'ayush'.
two_hop_friends = graph.traverse('ayush'). \
out_edge([('type', 'follows')]).node(). \
out_edge([('type', 'follows')]).node().execute()That wasn't so bad. Weaver's alpha release includes a number of node programs, such as breadth-first search, computation of clustering coefficient, and n-hop reachability check. And you can always write your own node program as well.
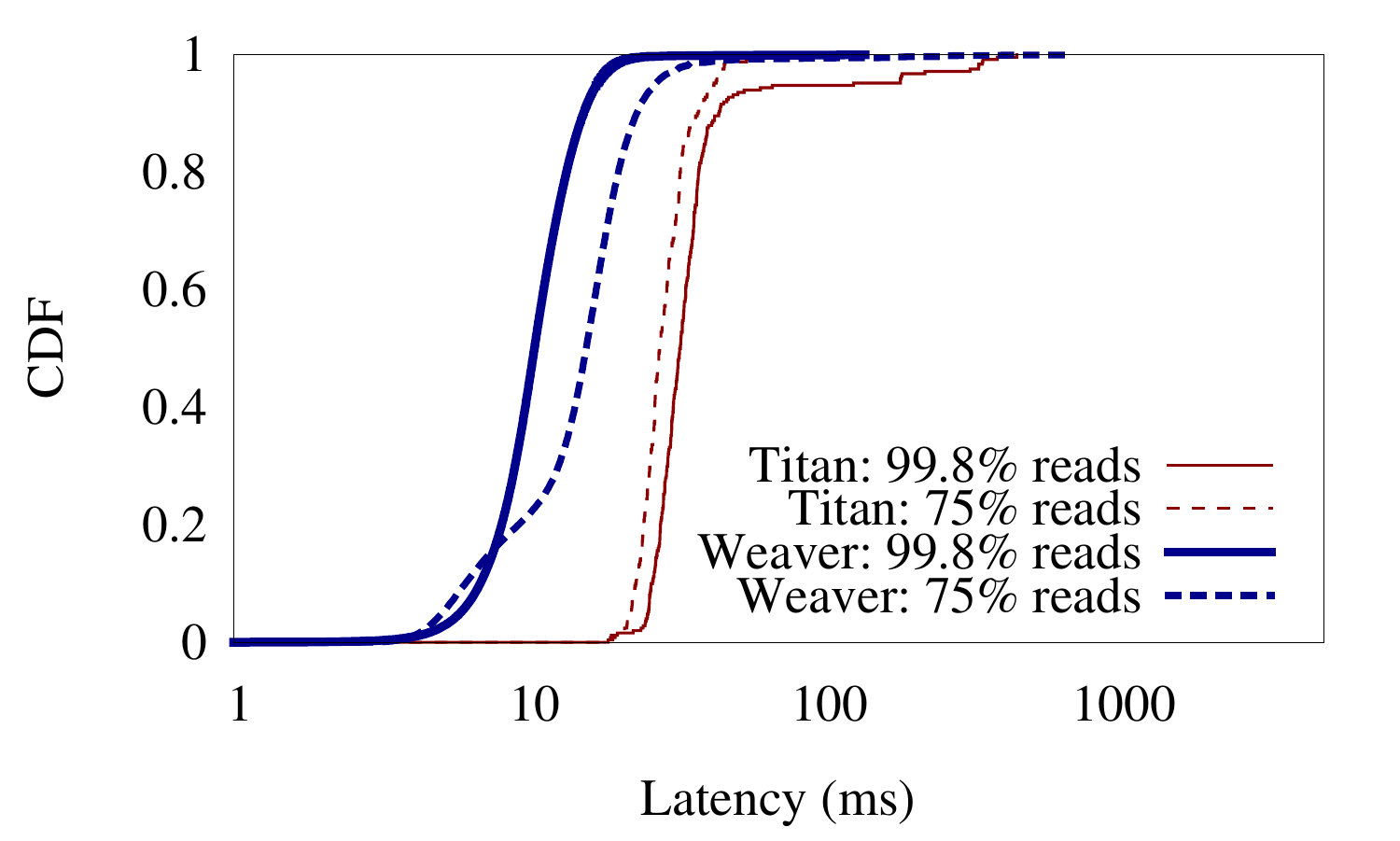
Performance of Weaver and Titan on the Facebook TAO workload.
We evaluated Weaver's performance on an online social network workload that mimics Facebook's TAO workload. Weaver gave over 12X higher throughput compared to Titan, a popular distributed graph store. Weaver also gave consistently lower latency for read-mostly workloads shown in the figure on the right.
Additionally, we also evaluated Weaver's performance on complicated, traversal-oriented graph queries. Weaver achieves 4.3X lower latency on random breadth-first search traversals compared to GraphLab [GLG +12].
Weaver stores its data reliably in HyperDex Warp, a fault-tolerant, transactional key-value and document store. If a Weaver server fails, a backup server assumes ownership of the data stored on the failed server and restores it. Weaver can withstand a configurable number of simultaneous failures.
Weaver is open-source under the 3-clause BSD license. You can download it or play with it in docker.
| BACC+13 | Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov, Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov, Dmitri Petrov, Lovro Puzar, Yee Jiun Song, and Venkat Venkataramani. TAO: Facebook's Distributed Data Store For The Social Graph. In Proceedings of the USENIX Annual Technical Conference, pages 49-60, San Jose, California, June 2013. |
| GLG +12 | Joseph E. Gonzalez, Yucheng Low, Haijie Gu, Danny Bickson, and Carlos Guestrin. PowerGraph: Distributed Graph-Parallel Computation On Natural Graphs. In Proceedings of the Symposium on Operating System Design and Implementation, pages 17-30, Hollywood, California, October 2012. |

PhD student at Cornell University interested in distributed systems. Current project is Weaver, a distributed, scalable, consistent graph store. more...

Hacker and Ph.D. student at Cornell, focusing on distributed systems and systems in general. Current projects include HyperDex, Replicant, and applications built on top. more...

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools