
The Lachish letters. British Museum CC BY-NC-SA 4.0
Ostraka (singular: Ostrakon) are pieces of ancient broken vessels and clay pottery. Their abundance in the ancient world made them a cheap and popular choice for writing notes and receipts, instead of the more expensive papyrus. The text was often scratched into the pot-sherd, and many were preserved to this day.
There is a lot of interest in building high-throughput blockchains. These are useful in decentralized open settings (BCH, Ethereum) as well as industry (Hyper ledger) and government applications (central-bank crypto-currency). We present here a new approach to advance towards this goal, but first, let's take a look at the state of the art.
Since Nakamoto's Bitcoin, the community has made significant progress in scaling blockchains. New generations of protocols solve the consensus bottleneck. Starting from Bitcoin-NG (implemented, e.g., in Waves-NG, Aeternity, LTO), followed by Byzcoin, Thunderella; non-serial solutions such as Phantom; Proof-of-stake protocols such as Ouroboros and Algorand; as well as other approaches such as Avalanche. That's just to name a few. Transactions can, therefore, be processed at fairly high rates -- now limited by the nodes of the system: Since each node processes all transactions, the system's rate is bounded by that of a single node.
One solution to blockchain scaling is layer-two solutions, namely payment channels, most prominently the Lightning Network, but also Duplex Micro-payment Channels, Teechain and Plasma. However, they require either synchrony assumptions (Lightning, Plasma) or trusted hardware (Teechain). They also require layer-one resources, as opening and closing a channel needs to happen on the blockchain.
Another proposed direction to assure participating nodes are able to handle the required capacity is known as sharding. Sharding is the process of partitioning the system nodes into groups where each group processes only a subset of the transactions. Elastico, Omniledger, Rapidchain, Ethereum 2.0 and others apply this sharding approach, allowing commodity laptops to be nodes. However, its security relies on the assumption each shard has sufficiently many nodes: sharding degree is decided at the system level, and if a shard is not allocated enough nodes then it is more vulnerable to attacks. In addition, cross-shard transactions are a challenge as transaction often affect multiple shards.
Ostraka is a new blockchain processing architecture that overcomes these challenges by taking a different approach. We eliminate the bottleneck of transaction processing by scaling the bandwidth, processing, and storage of the nodes. In practice, we scale by implementing each node with multiple machines that operate together as a single node. Unlike previous sharding solutions, Ostraka is sharding the node rather than the system. The concept of the node-sharding has been discussed in the community, (e.g., this Bitcoin Cash community blog post), sometimes called local sharding. We design the full architecture and provide measurements and analysis, showing it can be a viable prospect for scaling blockchains into the future.
Note that the implication of the Ostraka architecture is that full nodes are more expensive to operate. Hence, they are likely to be run by larger actors with special interests such as miners, payment processors, exchanges, and research institutes. Probably law enforcement agencies as well. For such larger players, the added overhead of operating a larger node is not significant, think of a 10-30 machine rack. Smaller operators such as hobbyists would have to suffice with a light-client protocol, however, this is already a necessity for the majority of clients who operate a wallet on a mobile device.
We outline here the architecture of Ostraka, present benchmark results and discuss security. For more details do check out our technical report.
Ostraka operates in the UTXO model, presented in Nakamoto's seminal Bitcoin paper (see here for background on the UTXO model). Blockchain nodes using the UTXO model maintain three data structures:
When sharding, Ostraka splits each of the three data structures among the servers of a node. We shard by transaction ID, namely the unique hash of its contents. This is the same hash used by transactions inputs to reference their source outputs. Therefore, we can identify which shard is responsible for which transactions, e.g., by taking the most significant bits (MSB) of the transaction hash, and know which shard to access when searching for a particular UTXO. Actually, sharding by MSB makes the system vulnerable and instead each node reshuffles its transactions. We further elaborate on security aspects below.
A shard assigned to a transaction is responsible for storing it, verifying its correctness and storing its unspent outputs. As each transaction hash is uniquely mapped to a single shard, in a node of K shards, each shard is responsible for about 1/K of the transactions.
The operation of the shards is orchestrated by a single server called the coordinator. The coordinator is in charge of all operations that are not directly affected by block size (O(1) operations). It is responsible for finding other peers on the network, tracking the head of the blockchain, etc. The coordinator in a node is connected to the coordinator of its peer nodes, and each shard in a node is connected to the shards at each of its peer nodes. This way, shards can communicate directly with one another, without passing all information through the coordinator.
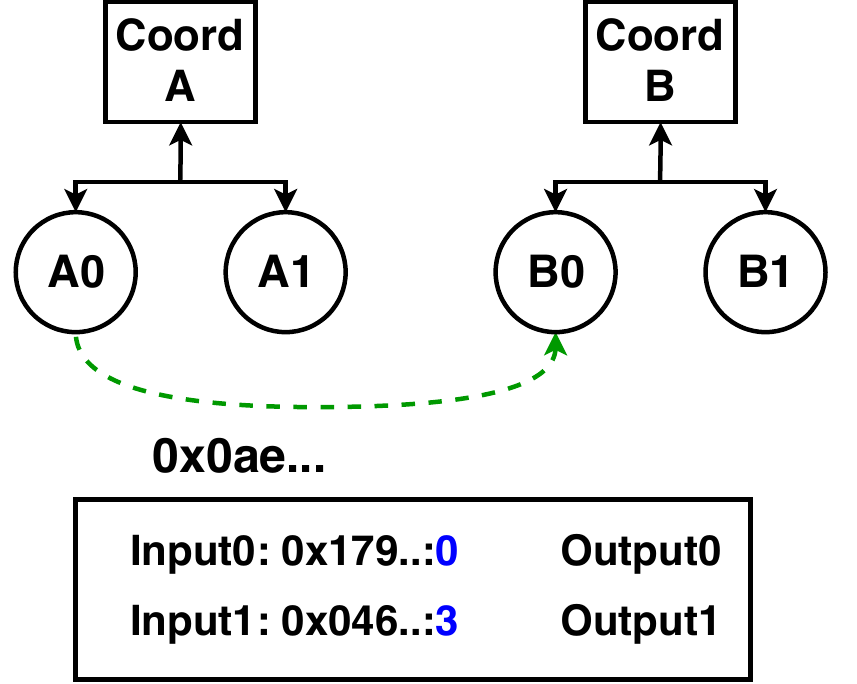
To illustrate the system's operation we take for example two nodes, A and B, each with 2 shards (A0, A1, and B0, B1). When receiving a new block, the coordinator of node B first receives from its peer (A's coordinator) the new block's header. It validates the correctness of the header metadata (PoW, time, etc.) and notifies its shards of the new block. Now, the shards B1 and B2 of B download from their counterparts A1 and A2 the appropriate transactions.
Once these are received, full block validation can occur. Each of the shards checks each transaction in its list to see where its inputs reside. In a node with K shards, approximately (K-1)/K of the referenced outputs required to validate the transactions are stored on sibling shards (B's shards). Thus, each shard requests the missing outputs from its siblings and collects them.
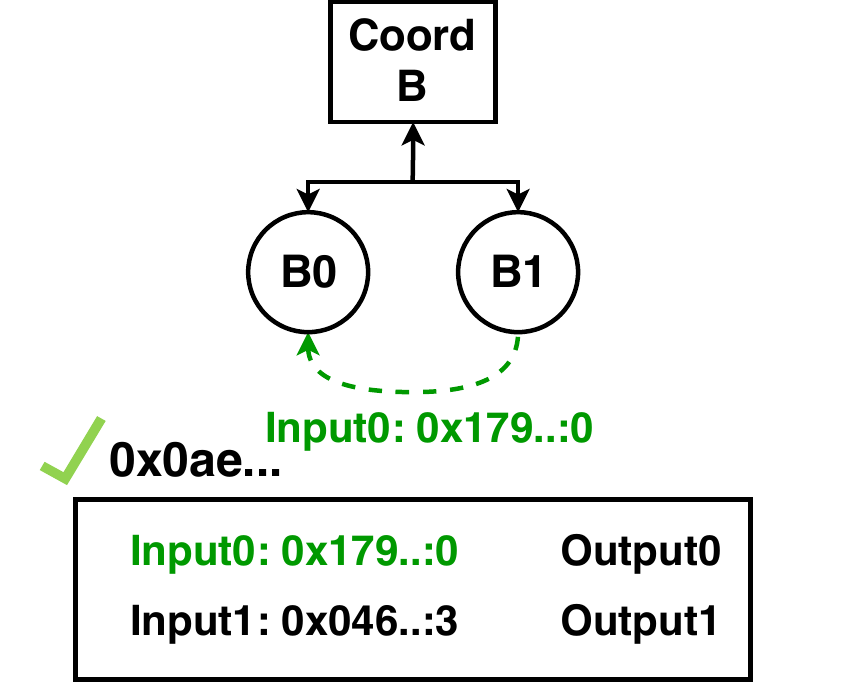
Next, each shard can validate its transactions, while monitoring for double spends due to local or remote transactions. Each shard is responsible for different transactions, and any one of them can detect a double spend if an output is consumed twice, that is, requested by more than one sibling. If some shard detects a double spend or an attempt to spend a non-existent output, it reports to the coordinator that the block is invalid. Otherwise, once all shards report their transactions as correct, the coordinator marks the block validated and can send it to the next peer.
Both a unified single-laptop blockchain node and an Ostraka 32-server node can process blocks of any size, it is only a question of how long it will take. Long validation time per node means the whole system operates at lower throughput (e.g., more forks in a Nakamoto-like blockchain). The interesting question is therefore how quickly processing is done, or how much processing you can do within a bounded amount of time.
For the benchmark we present here, we chose a time target of 10 seconds -- block processing should not take longer than that. We chose this limit arbitrarily, this way we can compare the system apples-to-apples with the changing number of shards as the only parameter. Designers of an operational chain should choose a target time according to their specific considerations.
We have implemented a prototype of Ostraka, based on the Go Bitcoin/Bitcoin-Cash client btcd, bchd. We measure the time it takes for the receiving node to process a block with an increasing number of transactions.
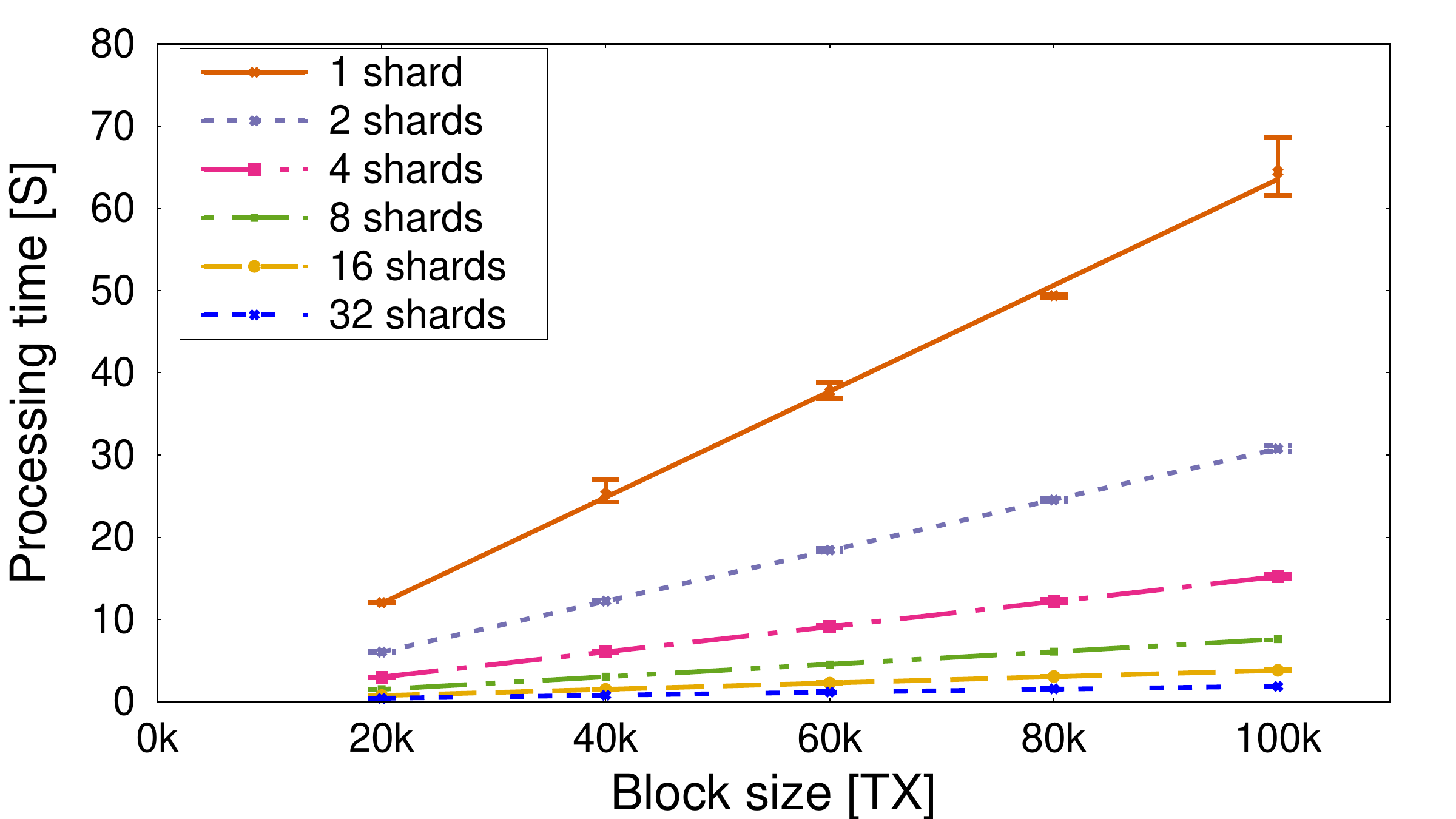
As we add more shards, Ostraka architecture demonstrates linear scaling, that is, by doubling the number of machines in a node it can process twice as many transactions per second, despite dependencies among them. This is the best we could hope for.
Current UTXO-based node implementations are already mostly parallelized. However, they remain limited by the hardware available by CPU vendors and system memory available on a single machine. These are limited by Moore's law, that has been winding down in the past years. By using multiple machines, we can break away from these constraints, and use as many machines as needed.
Then there are additional benefits. We are not distributing processing effort only, but data structures as well. This speeds up I/O operations and data access. With only a partial UTXO-set managed by each shard, it is easier to keep all of it in fast system memory, instead of slow storage devices. Database lookup times are also accelerated, as there are now fewer entries to search through.
The following image of our measurement shows how we achieve nearly perfect scaling when doubling the number of shard 2X, 4X, and 8X. Simply doubling the number of cores by the same factor achieves poorer results, and is, of course, limited by the number of cores on a CPU.
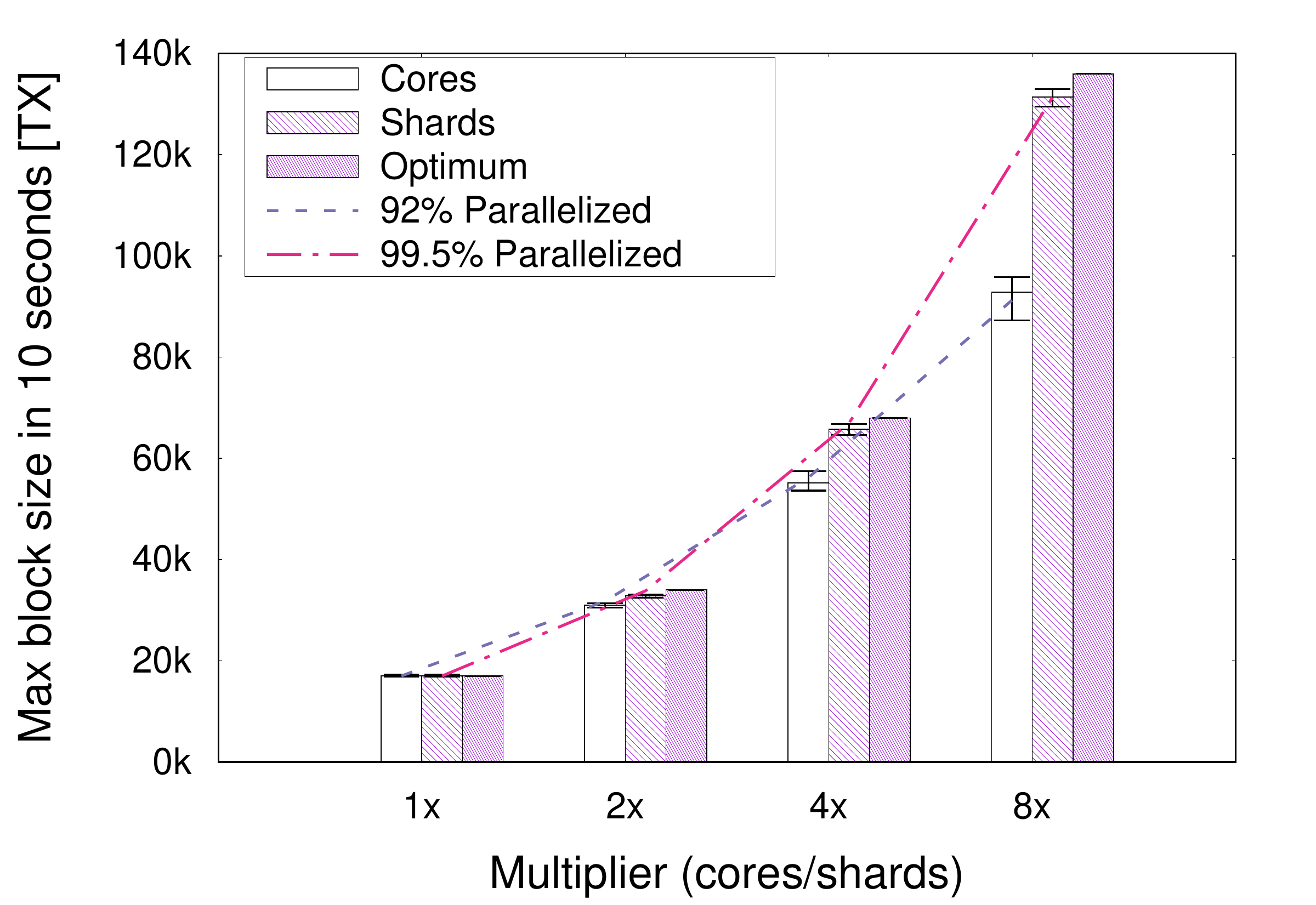
We can, of course, use multiple servers with multiple cores to achieve even better performance. By using a node of 64 shards, we measured processing capacity of 400,000 transactions per second.
At first glance, it might seem that adding more shards might reduce performance, as more messages are required for cross-shard communication. The latter is true, but as the number of shards grows, the number of transaction outputs each shard is responsible for actually decreases. On average, given a node with K shards, each is responsible for 1/K transactions and transaction outputs. It must also request an average of (K-1)/K of outputs to validate a block. When processing a block, it requests ((K-1)/K)(1/K) outputs, (or O(1/K)). Thus, although the number of messages each shard needs to send increases, the overall number of bytes each shard sends (and receives) also decreases linearly with the number of shards. In addition, since shards are in close physical proximity and connected by a high-bandwidth network, inter-shard communication is cheap.
Ostraka is a node architecture that can be incorporated into existing blockchain protocols. We thus need to make sure that the change to the node architecture does not harm the underlying protocol. To do that, we first show in our report that the unified architecture and Ostraka are logically indistinguishable. Specifically, we show that despite changes to the node structure and validation details, an Ostraka node performs the same steps of block validation as a unified node does.
Preventing denial of service is trickier. For an Ostraka node to complete block validation quickly, all shards must work in parallel to accomplish the job. If it takes too long for one of the shards to validate its share, the entire process is slowed down and the benefits of the distributed architecture are forfeited. To accomplish this, an attacker could try to create a block where all transactions are mapped to a single shard.
To prevent such attacks, Ostraka nodes shuffle their transactions. Each node picks a unique salt value and uses it to locally reshuffle the transaction among its shards. Technically, instead of sharding by directly by transaction-ID, the transaction hash is hashed again with the salt to form the sharding index. By creating a unique transaction distribution on each node, the difficulty of an attacker to create such a malicious block drops exponentially with the number of nodes it attacks.
Blockchains provide an open and decentralized payment system accessible to anyone with an internet connection. There is wide interest in making the technology must be able to handle the demand of anyone who wants to participate.
Ostraka removes the bottlenecks of the individual node of a blockchain system, without undermining the system's security. It is not a new consensus protocol but rather an architecture to enable protocols to reach their full potential. We see Ostraka as another piece of the puzzle for building the next generation of blockchains, capable of handling the demand for a practical decentralized global payment system.

A post-doc in the Systems and Networking Group in the Department of Computer Science in Cornell. My Research Interests are distributed systems and algorithms, specifically distributed storage algorithms, the distributed aspects of Bitcoin, and reliable aggregation in distributed sensor networks. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools
