Today's post is a cautionary tale on why running a lottery on a blockchain is so incredibly hard to get right [1].

Here's the setting: Eric Lombrozo, a Bitcoin Core developer, was in the Christmas spirit yesterday and decided to give away 1 BTC, split into 10 chunks of 0.1 BTC each, to people who re-tweeted him. This is a gift of approximately $1500 [2] each.
He wanted to make the giveaway provably fair, so he devised the algorithm described in his tweet thread. I won't go into the gory technical details at all, except to note that, in essence, he wants to pick a random number, say 17, and give out 10 awards to every 17th person. To do this, he combines two block hashes at a pre-determined block height and derives a 16-bit number (H) that is coprime to the number of retweets. Coprime, also known as "relatively prime," just means that the winning lottery number H and the number of re-tweets do not have a divisor in common. He then indexes into the list of re-tweeters 10 times, rewarding every (H)th retweeter, wrapping around as necessary.
Now, the scheme is quite ornate and complicated. But the key operation that's happening underneath is simple: he is deriving a random number from two block hashes. This is a pattern I've seen in use in at least a dozen buggy Ethereum Dapps, and many of you are going to stop reading at this point thinking you understand the problem. Do read on, because there are multiple problems, and the actual bugs are not the usual, obvious ones, even though it'll seem that way at first.
Let's delve into this scheme and note the interesting observations and thoughts as we go along:
This scheme is ostensibly quite worried about miner manipulation of the lottery.
Everyone deriving random numbers from block hashes should worry about attacks by miners. Recall that a miner wishing to tilt the lottery can do so by computing a block and seeing if its hash yields a good outcome for the miner. If not, the miner tosses out the block without making it public.
But in this case, this worry about the miners is completely overblown. A miner would have to be insane to discard a perfectly good block to tilt this particular lottery, because they would stand to lose more than 20 BTC (~$300,000) for a gain of 0.1 BTC ($1500).
Regardless, some people are overly paranoid about things that will not happen. We have heard quite a bit about the "Chinese miners" [3] and there is a subreddit dedicated to villifying them. And Core developers keep reminding us how cautious they are as a group. Perhaps the extra paranoia is called for; at least, maybe it's harmless.
But is extra paranoia really harmless? Or as Ross Anderson has argued relentlessly for a few decades, should one make security decisions based on costs? Is computer security, at its heart, a game of tradeoffs, where quantitative reasoning should keep us from going towards unnecessarily ornate solutions, which, in their effort to guard against things that are not happening now and will not happen in the future, themselves introduce other flaws? Even if they don't introduce problems directly, they take our time and concentration away from other potential issues. While we're trying to focus on the miners, we might totally miss the boat on other, bigger problems, right?
Things get philosophical at this point, so I'll abandon this line of thought and assume that the miners are evil. There is a subreddit full of messages and memes to this effect.
So how good is this approach at keeping the evil miners at bay? Not at all. This scheme derives a random number from the combination of two hashes, at heights h and h+5. It does not make sure that these blocks came from two separate miners. What's the point of picking two numbers if they are coming from the same entity?
And even if blocks h and h+5 were coming from different miners, how do we know that they are not colluding? This seems like an insurmountable problem.
But no matter! This scheme is broken anyway, in the usual, predictable way. The miner who mines the second block knows the first one, so he is fully and solely in control of the lottery's outcome. So, the two miners don't even have to collude, the second one controls the outcome. If there had been N miners, the last one, alone, would control the outcome.
But wait, the flaw in the randomness computation does not matter, because rational miners won't launch attacks that cost more than the potential winnings, let alone attack a good will gesture. Now, if this was a state lottery, it would be a different story, but it isn't, so let's move on. All the energy spent worrying about miner attacks is wasted.
This brings us to the crux of a more fundamental problem. This particular scheme picks a random winning number and awards multiples of that number. And the picked random number is restricted to coprimes of the group size. Combined, this choice of H, and the selection of H*j mod N, restricts the set of winners.
As a result, some numbers are much more likely to be chosen for H than others. A simple example illustrates why. Imagine that Eric's tweet gets 1000 retweets. There are 65534 potential numbers that can be coprime with 1000. For instance, 2, 4, 5, 6, 8, and 10 are not coprime, so they will not be the first picked number. Their multiples are not going to be chosen either.
Now, it could be that a smaller number is picked, like 1, and the first 10 numbers would then be covered, including 2, 4, 5, 6, 8 and 10.
And it could be that a large number is picked, and it wraps around and covers numbers that would otherwise not be covered.
But there may well be numbers that are neither covered by getting picked (i.e. coprime with N) nor covered by a large number wrapping around (i.e. a multiple of a coprime mod N). Let's call these unlucky numbers.
Are there such unlucky numbers? Yes, it turns out that, if there are 1000 tweeters, there is absolutely no way that tweeters 20, 25, 40, 50, 60, 75 would ever win!
We don't know how many retweeters there will be. So perhaps the unlucky numbers for 1000 tweeters are different enough from the unlucky numbers for 1001 tweeters, and the probabilities cancel out?
We could do some number theoretic analysis at this point, but it's Christmas Eve and it's a lot easier to just crunch the numbers and check. What we can do is iterate over the possible numbers of re-tweeters, and see if there are any favored positions and unlucky numbers, and then we can see by how much the favored people are ahead of the unlucky ones.
I wrote a little simulator that examines what happens for every number of re-tweets. It's on github here. Everyone can look and see for themselves if I missed something.
Here are the results in graphical form, for a number of re-tweets in the range 1000 to 4000.
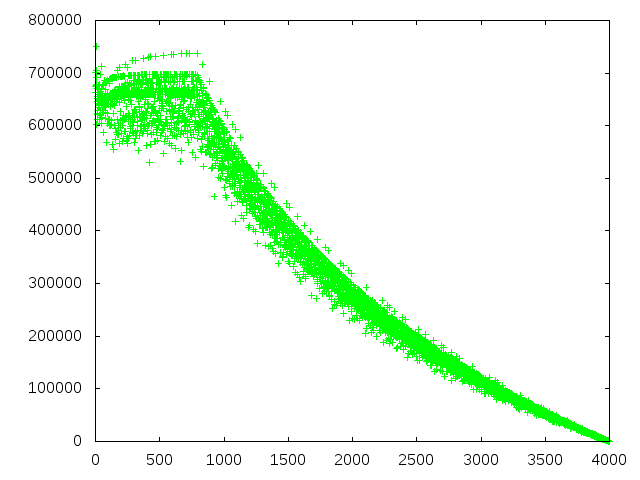
We can immediately see that, of the 1000 people who have already retweeted Eric, re-tweeter number 10 is highly favored! He has 641486 different ways he can win. Second favorable position is person 970, who has a respectable 632404 ways to win. Retweeters 2, 8 and 9 are also in the top-25.
Winners Losers ------- ------ 10 641486 143 475215 970 632404 336 473269 890 632321 672 472628 830 631763 756 470375 790 631226 528 468487 730 630904 840 464022 710 630818 780 461876 670 630004 660 455016 610 629438 420 454108 590 628902 924 440952
Compare this with the losers at the tail. Retweeter 924, for instance, has only 440952 ways to win! Retweeter #10 is almost 1.5 times more likely to be chosen than retweeter #924! His compatriots at 420, 660, 780, 840, and 528 are other lacklusters who are much less likely to be chosen.
That all seems very clever. It initially looked like the mechanism was manipulable by miners, but then it turned out that that was totally irrelevant and the scheme was flawed all by itself. The distribution is not uniform; it favors certain people.
But there is a much bigger, even more glaring error. I'll give you a paragraph break to think about it.
This lottery is actually tilted in favor of people who run social media manipulation services. If you have a bunch of twitter sockpuppets, you can occupy many more slots than honest people. None of the fancy math and simulations above actually matters if you have 1000 sockpuppets and there are only 1000 organic retweeters. The sock puppets' chances of winning will be 50%.
What would be a better way? Uniform distributions are actually difficult to get right. As is often the case, the simplest solution is the best: take the list of re-tweeters, and shuffle it (using a Knuth shuffle [4]) based on a random number seed derived from the block hash. You can then give out awards to the top 10 people. The shuffle algorithm has to be known in advance so people don't think that you reorganized the list to award your friends and family, but that's straightforward. And yes, you're still subject to Sybil attacks even with this scheme.
But having announced a particular lottery scheme, can Eric change it on the fly? If this were a smart contract, that would be tantamount to a hard fork!
So, what did we learn from this exercise?
| [1] | Actually, as with every Bitcoin related tale these days, this discussion contains, fractally, the entirety of the block size debate within it. |
| [2] | Specifically, it's $1340 at the time of this writing, minus $40 to receive the funds, minus another $40 to use them. |
| [3] | The "Chinese miners" are almost always lumped together by their nationality as if all of them come from the same mold. Yes, it's inappropriate. |
| [4] | Many thanks to Nick Johnson for pointing out that a previous suggestion to use millions of swaps is inefficient and only asymptotically achieves a uniform distribution. Knuth spends considerable time on this topic and provides an efficient solution. |

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools