As you're undoubtedly well-aware, there are some very strong geek fashion trends in the valley. I don't mean fashion in the sense of geek haute-couture -- the fashion trends we're talking about here have to do with tech components. You've heard of it before: "here's how we built fubar.com using X, Y and Z." The blogosphere regurgitates this dreck, and people base their adoption strategies on how much noise they have heard about various X's, Y'z and Z's.

A mockery of good engineering.
This kind of software construction is the modern equivalent of the bolt-on motorcycle shows on TV. You know the shows where the main bro-mechanics spend at most 5 minutes of any 44-minute show actually building something, combining the least amount of effort with the maximal amount of personal aggravation and bickering, very much like a soon-to-fail valley startup. They spend absolutely no cycles on essential design. No part is ever sized or spec'd or chosen for its merits, or for any reason besides looking like the other cool kids. The core of the operation, the engine, comes ready-made from a factory and is bolted onto the frame any which way that fits. The frame is most certainly not aligned with anything more precise than a pair of eyeballs. The only thing the builders spend their time on are useless design elements (e.g. "we welded this head of a 5-iron golf club onto the gas tank since the owner loves to golf"). It's as if the whole show was designed to mock American engineering.

MongoCycle: unsafe at any speed.
For a while, I thought that the problem with this approach was that the engineering had been outsourced. But that's not the problem at all; there is nothing wrong with reusing components designed by other people. The problem here is that the thinking has been nullsourced -- there is none taking place on or off set. These guys put these weird-looking bikes together this way solely because they've seen others do the same. They question none of the assumptions, can provide no performance guarantees, and they don't even check how the bike handles.
And us geeks are no better. There is no shortage of valley startups where component selection is based on hearsay alone, where group-think and blog noise determine what components get used, and frankensoftware is pieced together by slapping together components without thinking about how they mesh together. I want to focus on just one popular software component today, called MongoDB.
MongoDB is a NoSQL data store. NoSQL offers a range of features, namely, performance, cost, scale, and elasticity, that are at best difficult and expensive, if not impossible, to achieve with traditional databases. So MongoDB could be cool. In fact, it used to be cool, because it was one of the earliest NoSQL systems out there, but there are second-generation data stores now and we can afford to apply normal standards. And by any standard, a data repository, especially one whose main selling point is high scale, needs to deal with failures.
So, let's imagine that you're building an Instagram clone that you'll eventually sell to Facebook for $1B, and see if we can accomplish that with MongoDB. Your site probably has a front-end web server where users upload data, like putting up new pictures or sending messages or whatever else. You can't really drop this data on the ground -- if you could lose data without consequences, you would just do precisely that all the time, skip having to configure MongoDB, and read all those dev blogs. And if you possess the least bit of engineering pride, you'll want to do an honest stab at storing this data properly. So you need to store the data, shown in yellow, in the database in a fault-tolerant fashion, or else face a lot of angry users. Luckily for you, MongoDB can be configured to perform replication. Let's assume that you indeed configured MongoDB correctly to perform such replication. So, here's the $1 billion dollar question: what does it mean when MongoDB says that a write (aka insert) is complete?
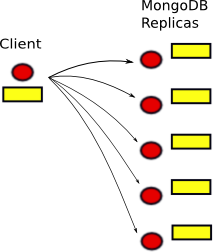
A. When it has been written to all the replicas.
C. When it has been written to one of the replicas.
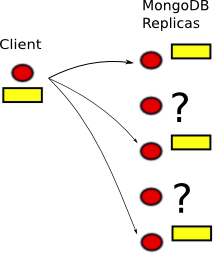
B. When it has been written to a majority of the replicas.
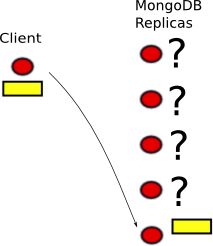
The answer is none of the above. MongoDB v2.0 will consider a write to be complete, done, finito as soon as it has been buffered in the outgoing socket buffer of the client host. Read that sentence over again. It looks like this:
D. When it hasn't even left the client.
The data never left the front-end box, no packet was sent on the network, and yet MongoDB believes it to be safely committed for posterity. It swears it mailed the check last week, while it's sitting right there in the outgoing mail pile in the living room.
Now, if machines crashed infrequently or never, this design choice might make sense. People with limited life experience can perhaps claim that failures, while they might "theoretically" happen, are too rare in practice to worry about. This would be incorrect. Hardware fails. More often than you'd think. System restarts are quite common when rolling out updates. Application crashes can occur even when using scripting languages, because underneath every type-safe language are a slew of C/C++ libraries. The software stack may need a restart every now and then to stem resource leaks. Bianca Schroeder's careful empirical studies show that failures happen all the time and if you don't believe academic studies, you can talk to your ops team, especially over a beer or five. Failures are common; it'd be silly to pretend they would never strike your system.
Since NoSQL systems depend fundamentally on sharding data across large numbers of hosts, they are particularly prone to failures. The more hosts are involved in housing the data, the greater the likelihood that the system as a whole will encounter a failure. This is why RAID storage systems, which spread data across multiple disks, have to spend some effort making sure that they're as reliable as a single large expensive disk. Imagine if you had invented Arrays of Inexpensive Disks (AID) back in the day, but weren't clever enough to invent the part involving the "R", namely, redundantly striping the data for fault-tolerance. I hate to break it to you but, far from applauding you for getting pretty close to a great idea, everyone would just make fun of you mercilessly. So, we can't just not replicate the data, not if we want to retain our engineering pride.
Now, seasoned MongoDB hackers will say, "wait! there is an API call named getLastError. Yeah, it's badly named, and yeah, it probably was not meant to be used to control fault tolerance, but it checks the number of replicas to which the last write was propagated. You could use that to see if your write propagated sufficiently for your fault tolerance needs." Ok, I'll play along. Let's see what it takes to use this call correctly.
First of all, using this call requires doubling the cost of every write operation. You would have to follow every insert with a getLastError to make sure that that write succeeded. This generates extra network traffic. Yes, there is some noise about piggybacking the insert with the getLastError request in the MongoDB code, but at the time of this writing, it is unimplemented. MongoDB disables Nagle, so your getLastError call will require a separate packet to the server. Your MongoDB performance, which was not the fastest to begin with, just took a dive.
Performance loss would not be a huge problem, except that MongoDB's entire design goal is speed. It compromises consistency and fault-tolerance to gain performance. But it's a strange Faustian bargain to give up on fault-tolerance and consistency, and to not end up with performance, either.
To get some performance back, you might have your thread pipeline its inserts. So your thread would perform "insert(A), insert(B), insert(C)". When you then issue getLastError(), and MongoDB says that the insert completed, which actual insert is it talking about? A, B or C? This is one area where the MongoDB documentation actually provides some explicit guidance and clarity. Here's what it says:
If the bulk insert process generates more than one error in a batch job, the client will only receive the most recent error. All bulk operations to a sharded collection run with ContinueOnError, which applications cannot disable. [1]
Great, the documentation explicitly says that there is no way to check for errors on any operation except the last one.
But further, unless you're building a joke of a site for which a scalable NoSQL data store is completely unnecessary, you'll have multiple threads performing writes in parallel. And what exactly does getLastError return when you've got 16 concurrent threads issuing 16 writes at more or less the same time? Which one of those 16 concurrent writes is the last one? The behavior of getLastError in a multithreaded environment is undefined in the MongoDB documentation. And in the actual implementation, the MongoDB Java bindings recycle connections in a connection pool between threads in a way that is completely outside the control of the programmer, so a getLastError call by one thread may very well end up returning information about the last write issued by another thread.
Now, the faults above are pretty damning, but the thing about badly-designed APIs is that there will be multiple, redundant alternatives for every task. For instance, the MongoDB documentation says that in lieu of calling getLastError() manually, one could use WriteConcern.SAFE, FSYNC_SAFE or REPLICAS_SAFE for the insert operation [2]. There are 13 different concern levels, 8 of which seem to be distinct and presumably the remaining 5 are just kind of there in case you mistype one of the other ones. WriteConcern is at least well-named: it corresponds to "how concerned would you be if we lost your data?" and the potential answers are "not at all!", "be my guest", and "well, look like you made an effort, but it's ok if you drop it." Specifically, that's three different kinds of SAFE, but none of them give you what you want: (1) SAFE means acknowledged by one replica but not written to disk, so a node failure can obliterate that data, (2) FSYNC_SAFE means written to a single disk, so a single disk crash can obliterate that data, and (3) REPLICAS_SAFE means it has been written to two replicas, but there is no guarantee that you will be able to retrieve it later. More on REPLICAS_SAFE and MAJORITY levels of concern in a future blog post; it's subtle, so it requires its own detailed writeup.

This frankenbike is probably more robust than a MongoDB-based website.
So, MongoDB is broken, and not just superficially so; it's broken by design. If you're relying on its fault tolerance, you're probably doing it wrong.
Edit: I wrote the blog entry above based on MongoDB version 2.0. It accurately reflects the state of affairs in the MongoDB universe for their first five years. Yes, a full five years of broken software.
In November 2012, a new version of MongoDB was released with a significant change. MongoDB drivers now internally set WriteConcern to 1 instead of 0 by default. While this is a change for the better, it is still not sufficient. To wit:
- This change does not make MongoDB fault-tolerant. A single failure can still lead to data loss.
- It used to be that a single client failure would lead to data loss. Now, a single server failure can lead to data loss for the reasons I outlined above.
- MongoDB is now a lot slower compared to v2.0. On the industry-standard YCSB benchmark, MongoDB used to be competitive with Cassandra, as seen in the performance measurements we did when benchmarking HyperDex. Ever since the change, MongoDB can no longer finish the entire benchmark suite in the time allotted.
Edit #2: Some MongoDB fans seem to be reading only until they see the first problem, the one involving the default setting of WriteConcern NONE. MongoDB has been criticized so widely over this issue that this has become a well-known sore point for them. So your Joe MongoDev, with a pre-prepared reaction to this well-known problem, stops the moment he sees it and starts writing responses that say that this problem was fixed, or would only be fixed if I read the manual.
I read the manual. I even quoted it. I also read the code. I named so many other problems besides the NONE problem that I actually lost count. I say explicitly that the simple fix in v2.2 is not sufficient. The code doesn't work when pipelined or multithreaded. Those SAFE settings don't work, and I explain why for all but REPLICA_SAFE, which I'll handle in a future blog post because it's kind of subtle, and clearly, it's already too taxing for some people to read a blog post of this length. If you're going to tell me that Mongo is this way because it's making some tradeoffs for speed, I already linked to benchmarks that show that, even with these terrible tradeoffs, it is dog slow.
Look, I realize that we live in a TL;DR culture. I lived through 8 years of a non-reading president along with everyone else. I know that the brogrammers out there are constantly getting texts from their buddies to plan the weekend's broactivities, trying to decide in whose mancave they'll be setting up their lan party, and are thoroughly distracted in between futzing with their smart phones and writing a few lines of code per day by cutting and pasting it from stackoverflow. But it's really not ok to act functionally illiterate when you're not actually illiterate, when an advanced society that once put a man on the moon worked so hard to educate you.
Consistency and fault-tolerance are hard. Genuinely hard. The devil is always in the details, and it takes a concentrated mind to navigate through these waters correctly. I know a thing or two about building large, complex systems, and I've done this for quite a while now, and yet it still takes me all my attention. So, chances that a Mongo fan can engage only his hind-brain, react with "LOL, tl;dr, fixed in v2.2 with a one-liner as described in Mongo manual" and actually have something meaningful to contribute are absolutely nil.
At a higher level, this is not your typical blog, of the kind that consists of 2 or 3 paragraphs regurgitating something else gleaned from elsewhere on the Internet. It's different. It's written by a different kind of person than the typical blog regurgitator. It's written as a reaction to this very culture of non-thinking system development. And it targets a different kind, a thinking kind, of audience. So, some people will have to step up their game a notch or two if they want to be taken seriously.
--

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools