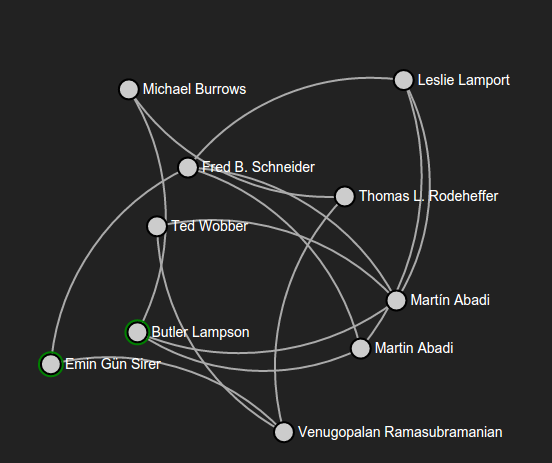
We recently put together a cute little data visualization tool that you may be interested in if you're a computer scientist. It enables you to traverse the collaboration graph of computer science research. It's similar to the Oracle of Bacon service that tracks people's distance to Kevin Bacon, except it lets you explore the world of geeky computer scientists instead of iconic Hollywood actors.
Specifically, it shows a dynamic graph in which each vertex is an author of a computer science research paper, where there is an edge between two authors if they have co-authored a paper. You can expand on authors by clicking on their names once, and you can go to their author profile by clicking twice. You can search for a specific single author, or you can explore the connection between any pair of authors by searching for a pair of comma-separated names. You can move the viewport by clicking on an empty spot and moving, and you can zoom in and out with the scroll wheel.
This demo was built to show our backend software. The system is built as a Flask application where the crucial graph data is stored in Weaver, a distributed, highly-scalable, transactional graph store, and HyperDex Warp, a transactional document and key-value store.
We are grateful to the CiteSeer project, from which we obtained a raw snapshot of the research papers in computer science.
Take a look, and see how many degrees of separation are between you and your favorite computer scientists.
Search is case-sensitive. Try capitalizing your initials. If your name has special accents, punctuation, middle initials, or contractions, try the formats that most other people use to cite your work.
We used the latest snapshot we could locate from CiteSeer. It does not cover everything up to the current day.
Indeed, the raw data from CiteSeer contains artifacts of the PDF extraction process.
We are happy to merge your code in that does something about it.
We are indeed a vibrant and collaborative community. The only downside of this great feature of our community is that the viewport can get cluttered. We are not GUI experts; in fact, we hardly know the first thing about GUIs. We will gladly merge in whatever improvements you may provide that make the viewport render better.
The CiteSeer project has done extensive research on author disambiguation and entity resolution, has more than a dozen excellent papers on the topic, and CiteSeer's own pages benefit from those algorithms. Unfortunately, the raw data snapshot we obtained from them does not contain the results of that data cleaning pass. So, one might appear in the authorship graph as multiple separate people with slightly different spellings and contractions of one's name. You are not alone, many of us feel your pain.
Not yet. While the merge is trivial to implement, protecting it from abuse and mistakes (e.g. merging unrelated people together) is non-trivial. Such an API faces the strongest adversary known to mankind: mischievous computer scientists.
But we are talking to the CiteSeer team to get the output of their entity resolution, as it makes sense to perform this as upstream as possible, and with the best custom-designed algorithms available. If that information is hard to extract from their data flow, we might provide a merge API in the future.
We currently cap the size of the search radius to 4 degrees to handle load. When the demand for the service is lower, we plan to expand the radius.
Sure. The front-end code for Research Trends is here. Weaver is free and open source, HyperDex is free and open-source, and HyperDex Warp has an evaluation version that is freely available in the HyperDex repository. We welcome all pull requests.

Visiting undergraduate from Shanghai Jiao Tong University. With Hao Chen, built the research trends website over two weeks, starting with no background on Flask, Weaver or HyperDex.

Visiting undergraduate from Shanghai Jiao Tong University. With Ted Yin, built the research trends website over two weeks, starting with no background on Flask, Weaver or HyperDex.

PhD student at Cornell University interested in distributed systems. Current project is Weaver, a distributed, scalable, consistent graph store. more...

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools