Some people have claimed that, with increasing RAM on modern machines, graph-structured data can fit on a single machine's main memory, and there is no reason for graph stores like Weaver, Titan and others to shard their graphs. A quick back of the envelope calculation shows that these concerns are misguided.
Let's take a typical social network application. Facebook has over 1.2 billion active users, and conservatively assuming each user has 50 friends, the friendship network has about 30 billion edges. When each node or edge has at least 1000 bytes worth of data associated with it, the resulting graph is around 30TB, far outside what can fit on a single machine.
And it gets worse. It is common practice for such applications to store the relationships between content in the same graph store as well [BACC+13]. So when we post new content, like a status update or a photo of the cat doing backflips, the application creates a new node in the graph store and writes metadata such as the time of creation, URI of the content, etc. The application also creates an edge between the node corresponding to the user who created the content and the content node. Any subsequent activity on the content, such as upvotes and comments, are also linked to the content via edges in the graph. Since users typically keep creating content while they are active on the social network, the graph-structured data stored in the graph store keeps growing, incommensurate with the underlying friendship network. Facebook reports that the size of the data they store in TAO is of the order of petabytes.
Many other domains, apart from social network applications, commonly create and manipulate many terabytes of graph-structured data. The Common Crawl Corpus consists of 5 billion crawled web pages totalling over 541TB of data. The 1000 Genomes Project has 200TB of biological genome data which comprise complicated networks. Knowledge graphs such as the Google Knowledge Graph and RoboBrain are rapidly growing datasets that contain semantic relations between data obtained from a multitude of sources.
But there are other reasons to shard the data besides its sheer size.
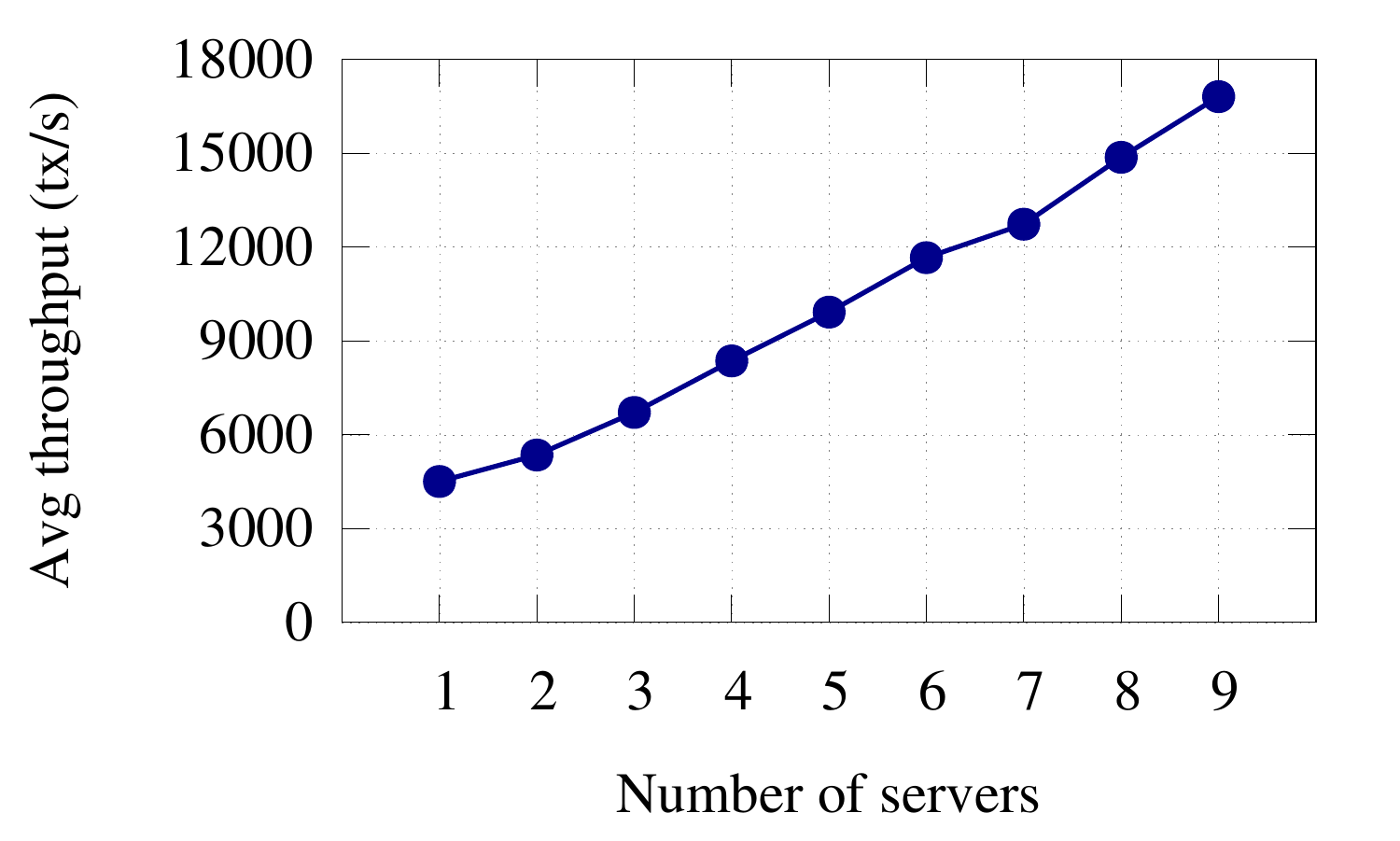
Weaver's average throughput for LCC computation scales with the number of servers.
Sharding a graph over multiple servers can be effective, even when the entire graph fits on a single commodity server's RAM, in order to parallelize graph query processing. Many common graph algorithms such as traversals or page rank are easily parallelizable. For example, a BFS query that starts at a node in the graph with three child nodes can explore the three subtrees in parallel. And the parallelism increases exponentially the deeper the query explores. This means that a commodity server's 16 cores will soon become a bottleneck on such kinds of graph computation. In the figure on the left, we show that Weaver's average throughput for computing local clustering coefficient of nodes scales linearly with the number of servers.
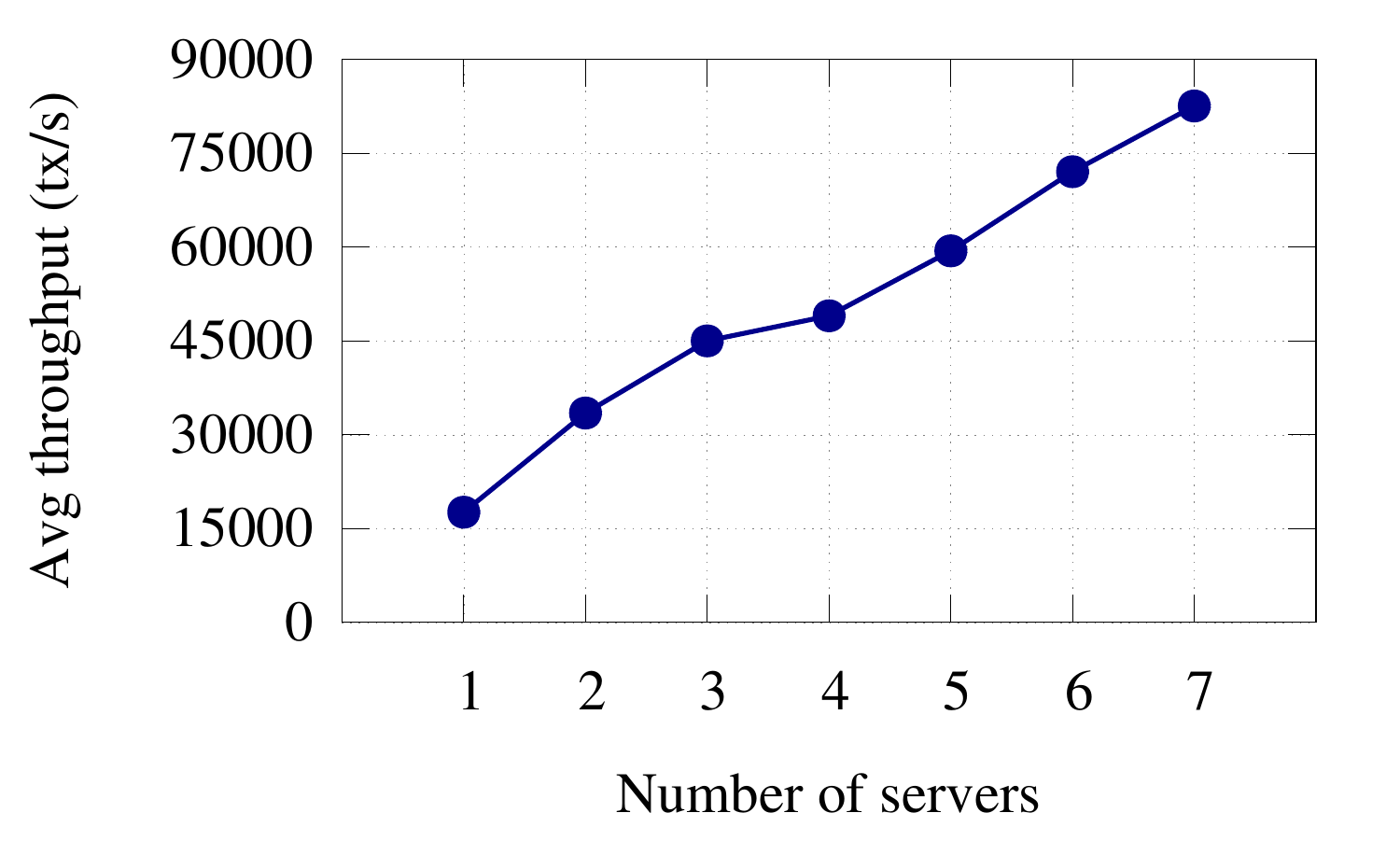
Weaver's average throughput for get_node ops scales with the number of servers.
Finally, even when the entire graph fits on RAM and the graph queries are single-threaded, it makes sense to shard a graph in order to scale beyond the number of requests that a single commodity machine can serve. A single host can only serve so many I/O ops/sec. The figure on the right shows that Weaver's throughput for get_node operations scales linearly with the number of servers.
Space, concurrency, and I/O throughput concerns call for sharding large graphs into smaller components. There is a final, fourth set of concerns: price, convenience and expandibility. Many of us would prefer to build a large graph store that scales gracefully and can be deployed on AWS than to buy a monster 0.5TB machine, let alone something bigger. The up-front cost is much lower, and of course, there is the peace of mind that comes from knowing that a system can scale up in an instant just by spinning up more nodes.
| BACC+13 | Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov, Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov, Dmitri Petrov, Lovro Puzar, Yee Jiun Song, and Venkat Venkataramani. TAO: Facebook's Distributed Data Store For The Social Graph. In Proceedings of the USENIX Annual Technical Conference, pages 49-60, San Jose, California, June 2013. |

PhD student at Cornell University interested in distributed systems. Current project is Weaver, a distributed, scalable, consistent graph store. more...

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools