In distributed storage systems, data is often partitioned across multiple servers for scalability and replicated for fault tolerance. The traditional technique for performing such partitioning and replication is to randomly assign data to replicas. Although such random assignment is relatively easy to implement, it suffers from a fatal drawback: as cluster size grows, it becomes almost guaranteed that a failure of a small percentage of the cluster will lead to permanent data loss.
There is a far smarter way place replicas, explored by a paper from our colleagues at Stanford, titled "Copysets: Reducing the Frequency of Data Loss in Cloud Storage" [CRSK+13]. It was presented at the USENIX conference, co-chaired by one of us, where it received the best student paper award. In this post, we want to first explain how random replica sets, as used in many NoSQL solutions, actually increases the likelihood of data loss, explain how Copysets mitigate the data loss risks, and then describe what it takes to render Copysets to practice in a NoSQL data store.
To gain an intuition for how random replication increases the chances of data loss, let's walk through a simple example on a cluster with a replication factor of three. A typical NoSQL data store will divide the cluster into shards, and the data in each shard will be replicated on three randomly chosen servers.
You can see that, as we add more nodes (as n, the number of total nodes in the system goes up), we will have more and more shards, each of which will contain 3 servers chosen at random. The more shards we have, the more of the 3-server combinations the system will contain. This is especially true for NoSQL systems that use virtual nodes to achieve load balancing. Eventually, we will have enough shards to exhaust all n choose 3 combinations of servers.
At this point, the simultaneous failure of any three servers anywhere in the cluster is guaranteed to lose data. There are only n choose 3 possible combinations, and the more of them that the system uses, the greater the chances are that a loss of 3 nodes will lead to a completely unavailable shard.
The figure below, reproduced from the Copysets paper, illustrates how the probability of data loss increases with cluster size.
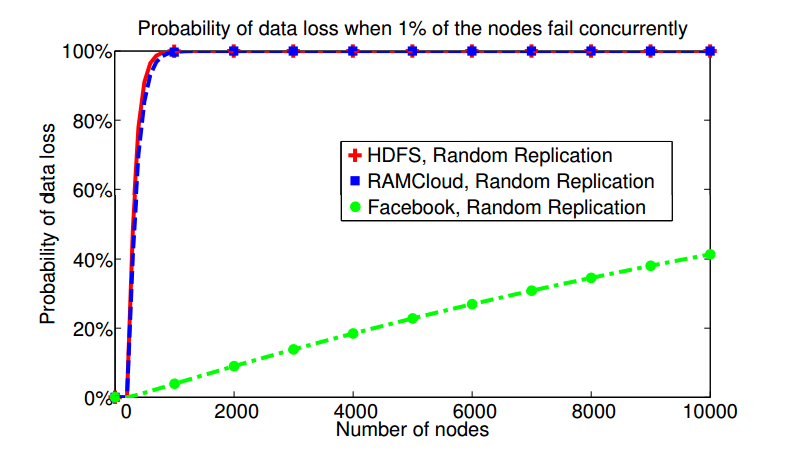
Traditional techniques for randomly selecting replica sets guarantees data loss as cluster size increases.
It shows that small failures affecting just 1% of the nodes can quickly increase data loss probability to 100%. The HDFS and RAMCloud curves are representative of the way random replication is deployed in many systems (and the Facebook curve hints at the insight that will allow the authors to improve on the state of the art).
The innovative idea behind Copysets is to limit the total number of replica sets generated. For example, we could pick our replica sets such that no server is assigned to more than one replica set. Instead of randomly generating all n choose 3 combinations, we would generate n/3 replica sets in which every server appears at most once. In this configuration, it's unlikely that killing a small number (~1%) of servers in the cluster would completely kill an entire replica set.
Of course, nothing comes for free, and Copysets embody two trade-offs. First, when a server fails in the Copyset described above, its replacement can only recover data from two servers, whereas with random placement, state can be recovered from every server in the cluster. In practice, the speed of recovery is typically bottlenecked by the incoming bandwidth of the recovering server, which is easily exceeded by the outgoing read bandwidth of the other servers, so this limitation is typically not a big deal in practice.
Second, there is a trade-off involving the frequency and magnitude of data loss. Random replication uses more replica sets, and incurs an increase in the frequency of data loss. Copysets reduce the number of replica sets, and reduce the frequency of data loss. In short, catastrophes become a few orders of magnitude more rare (from "one every year" to "one in a few lifetimes"). And it doesn't quite matter that one scheme loses a little bit of data while the other one loses more -- after all, in both cases, one will have to recover from backups (you're running a NoSQL system that can take instantenous, consistent and efficient backups, right? :-). It should not matter much how much data you have to recover; the main costs stem from the inconvenience of having to manually initiate a recovery.
Cidon et. al. express the latter trade-off as the scatter width of the cluster. The scatter width is the number of servers which hold copies for each server's data. As the scatter width grows, Copysets begin to approximate random replication. Going a level up, the scatter width for a cluster is the average of scatter widths for the servers. For example, a scatter width of two with a replication factor of three will assign each server to exactly one replica set.
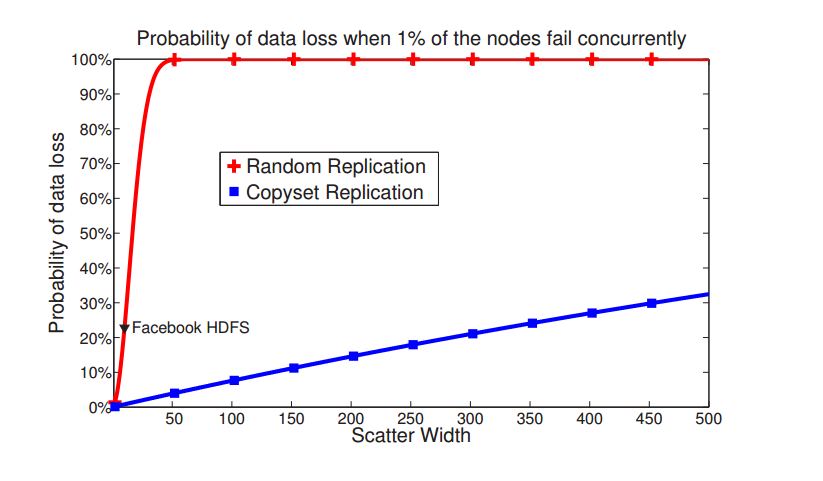
Data loss probability versus scatter width for an N=5000 cluster.
Let's see how this idea can be implemented in practice. The core idea is so elegant that it's pretty easy to code up, though it takes more effort than random replication.
Recall that the dumb random replication algorithm is just:
It's so easy that even MongoDB gets it right. Probably.
The algorithm for Copyset replication is only slightly more complicated. It takes as input a set of servers, a specified scatter width S, and a desired replication factor R. To generate the Copysets:
This will create a number of replica sets that achieve the desired replication factor while approximately upholding the desired scatter-width.
For example, consider a cluster with 9 servers and a replication factor of 3. If we specify a scatter width of 2, we'll need just 2 / (3 -1) = 1 permutation. Let's randomly pick this permutation:
[1, 6, 5, 3, 4, 8, 9, 7, 2]
In step two, we generate the replica sets by grouping servers from this permutation into groups of size 3:
[1, 6, 5], [3, 4, 8], [9, 7, 2]
We can see that every piece of data is 3-replicated, and in this instance with a scatter width of two, all replica sets are completely independent of each other.
Now is a good time to step back and contrast the Copyset approach with traditional practices in distributed systems. In a 5000 node cluster with replication factor 3, and where 1% of the nodes fail simultaneously, random replication would lose data 99.99% of the time. In contrast, under the same conditions, Copysets bring data loss probability down to just 0.15% of the time.
Let's also examine what happens when scatter width is set to four. In this case, Copysets will generate 4 / (3-1) = 2 permutations. Let's say that the two permutations are:
[1, 6, 5, 3, 4, 8, 9, 7, 2] [1, 2, 7, 5, 4, 6, 3, 9, 8]
For this cluster with scatter width four, the replica sets are:
[1, 6, 5], [3, 4, 8], [9, 7, 2] [1, 2, 7], [5, 4, 6], [3, 9, 8]
Note that this strategy does not always produce an optimal assignment because it is not possible to always do so. Some servers do indeed have a scatter width of 4, such as server 9, which is in replica sets with 2, 3, 7, and 8. Other servers, such as server 5, which appears jointly with server 6 in two separate replica sets, fail to have a scatter width of 4, but do come close with a scatter width of three. Determining the replica sets optimally looks like a very difficult, possibly NP-hard, problem, so this proposed randomized technique is a great way to get the benefits of Copysets without getting trapped in an intractable problem. The Copysets paper explores the costs of this assignment technique in more depth.
Because Copysets seem like an elegant way to reduce the likelihood of disastrous events in a cluster, we decided to implement them in HyperDex, the next-generation NoSQL data store that provides strong consistency and fault-tolerance guarantees, ACID transactions, high scalability and high performance. Because Copysets are an incredibly elegant idea, rendering them to practice is fairly straightforward, but there were two challenges when adopting them for use in HyperDex's chain replication.
First, it's not immediately apparent how to modify the algorithm for use in a dynamic environment, of the kind we face in a HyperDex cluster where nodes can be added and removed on the fly. The permutations generated by the Copysets algorithm are inflexible and generated prior to online operation of the cluster. Adding or removing servers in the middle of the permutation would require reshuffling all subsequent replica sets to accommodate the change. Adding new servers solely to the end of each permutation would reduce scatter width by creating redundant replica sets.
Second, Copysets are agnostic to the replication algorithm used by the storage system. In settings where the NoSQL system itself exhibits some structure, the default Copyset generation algorithm is oblivious to that underlying structure and can generate bad sets that require excessive data motion. In particular, HyperDex uses value-dependent chaining, a variant of chain replication, to store its data. We extended Copysets to take into account the structure of value-dependent chains.
Our implementation of the Copyset algorithm, which we've dubbed Chainsets, improves upon the Copyset algorithm in several key ways:
Copysets are a great alternative to random replication. If you are hacking on a data store that uses random replication strategies (or some variant thereof), you really owe it to yourself to check out the Copysets work and see it can reduce your expected frequency of data loss. We've switched the allocation strategy in HyperDex to Chainsets by default because it is strictly better than the random replication algorithm we had previously used as the default.
| CRSK+13 | Asaf Cidon, Stephen M. Rumble, Ryan Stutsman, Sachin Katti, John Ousterhout, and Mendel Rosenblum. Copysets: Reducing The Frequency Of Data Loss In Cloud Storage. In Proceedings of the USENIX Annual Technical Conference, San Jose, California, June 2013. |

Hacker and Ph.D. student at Cornell, focusing on distributed systems and systems in general. Current projects include HyperDex, Replicant, and applications built on top. more...

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools