
There are many letters in distributed systems, and they're not fungible.
It seems that newcomers to distributed systems are often confused by the various definitions of the C-word. I want to go over them to draw a distinction that is often overlooked, without getting into the tired old arguments around eventual consistency. Specifically, I want to expand on the distinction between properties of a data store and the properties of applications built on top.
But first things first. I searched for clarification on the different definitions of the C-word. All I could find was a claim that the C in CAP equals AC in ACID (an incorrect claim), and a clipped Twitter exchange (in the right direction but too short). And Wikipedia is absolutely horrible when it comes to distributed systems. So, let's look at the different definitions together and discuss how they differ from the real consistency people care about.

C as in CAP is about getting one's ducks in a row, also known as linearizability.
The "C as in CAP" is a narrow kind of consistency that pertains to how operations on a single item are ordered, performed and made visible by the database. Gilbert and Lynch, the theoreticians who formalized CAP, defined that capital C as "linearizability for a read/write register." A "read/write register" is an object in the datastore in this discussion, and what "linearizability" means, intuitively, is that all clients of a system would observe a uniform total order on operations on this object, with all operations taking place indivisably (atomically), and in accordance with an order that, loosely speaking, makes sense to the clients. Specifically, "makes sense" means that an operation that begins after another one has completed must appear later in the timeline. A linearizable data store behaves like a variable does in CS101; namely, a read will always return the value of the latest completed write (CS475, parallel systems, reveals that real memory systems are much more complicated than this, but also delves into mechanisms that cover up those complications to uphold this linearizability guarantee; these are beyond the scope of this discussion).
A system that cannot guarantee linearizability is free to return values other than what a normal programmer might expect. For instance, reads may return values that were written quite some time ago, or the values might move forward and backwards in time, or they might disappear altogether. There are various names given to classes of such behaviors, called consistency models, where "eventual consistency" is one of the weakest.
Needless to say, it's challenging to provide a linearizability guarantee in a distributed, replicated data store where messages can be delayed and failures can strike at any time. Many first-generation NoSQL stores explicitly forego consistency altogether, settling for eventual consistency. Such systems are, clearly, not "C as in CAP." In contrast, second-generation NoSQL systems, such as HyperDex, Google's Megastore and Spanner, provide linearizability. Every GET is guaranteed to return the results of the latest PUT.

C as in ACID is rich, complex and can express anything related to one's current or past states.
In contrast, the "C" in ACID refers to a broader kind of consistency that provides integrity guarantees that span the database itself. Whereas the "C as in CAP" relates solely to the ordering of operations on a single data item, the C in ACID refers to abstract properties that can involve any number of data items. "C as in ACID" is a strict superset of "C as in CAP," and it is a lot harder to achieve, as it requires coordinating reads, writes, updates and deletions involving arbitrarily large groups of objects.
As an aside and a corollary to the definition above, a NoSQL system that claims to be "ACID-compliant on a per-item basis," or "ACID without transactions" makes no sense (and there are quite a few of these in claimed existence). A developer capable of building a trustworthy distributed data store would know better than to use that self-conflicting terminology. They really mean "C as in CAP plus D," but chances are that they are so confused about what they have implemented that it will come down to "I as in Inconsistent" and "DL as in Data Loss."
Very few NoSQL data stores provide "C as in ACID" guarantees, as these guarantees necessarily involve a notion of transactions spanning multiple objects. Since NoSQL systems are based on a sharded architecture, transactions across multiple objects necessarily involve coordination across many nodes. Such coordination, if done via a centralized transaction manager, violates the main tenet of the NoSQL approach, which is to scale horizontally through sharding. If done via conventional distributed coordination protocols, such as Paxos consensus/2PC/3PC, the coordination overheads can be excessively high. But a few second-generation data stores use very interesting techniques to provide "C as in ACID" guarantees. For instance, Google's Megastore uses Paxos subgroups to achieve consensus on a total order. Calvin uses batching and dedicated ZooKeeper transaction managers for the same task. Google's Spanner uses mostly-synchronized clocks to determine when operations are safe to commit. And HyperDex Warp provides "C as in ACID" guarantees (in addition to "C as in CAP" guarantees) through a novel, high-performance distributed transaction protocol.
The difference between these C's is crucial. For instance, "C as in ACID" enables a CEO to say things like "the number of records in the personnel database should be N, the actual number of people I have hired." Or "number of cars produced should be less than or equal to the number of engines purchased." Or "at the end of the data analytics run, there should be a single summary object for each region, containing accurate statistics of sales figures." Or "every Bitcoin transfer that has been executed should be reflected in the corresponding users' wallets." In general, C as in ACID encompasses any kind of property that can be expressed over collections of records, where these properties are application-specific, user-defined, and checkable functions over total system state.
A data store can be "C as in CAP" but fail to be "C as in ACID." A series of updates to the database that are individually "C as in CAP" can take the database through intermediate stages where they have been only partially applied to the data. Such intermediate stages may violate the "C as in ACID" requirements, even though they are applied individually to the data items in a "C as in CAP" manner. And these situations will not always resolve themselves. For instance, if one were to take a backup during one of those instances, resorting to the backup later might put the entire data store in a permanently bad state.
Of course, if a data store is only eventually consistent, it is not C as in anything, it's EC. EC provides only a weak guarantee that, some unbounded amount of time after the system quiesces (assuming it does indeed quiesce), the system will converge on the state of the final writes.
So, the ever popular question: Should a data store provide C as in CAP, C as in ACID guarantees or just eventual consistency? The answer is the question cannot be answered as posed.
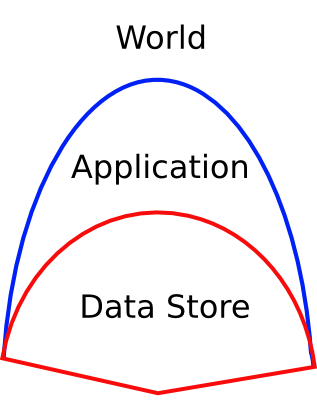
Users, the only people who matter, perceive the invariants upheld at the blue boundary. The properties of the red boundary may limit that of the blue.
The only thing that matters to a developer are the properties her application must possess, the invariants it must maintain at the application interface. For any real application, these invariants are typically very rich, very complex, and span a mix of both safety and liveness properties. They are certainly not limited to the constrained, and highly abused, alphabet one commonly sees in NoSQL-related blogs (e.g. Basically Available, Soft-state, Eventual Consistency, and Partition-Tolerance). Application-level invariants may span such issues as performance guarantees, bounds on failover time, reconfigurability, etc. They have a strictly richer vocabulary than what can be expressed through C as in CAP or C as in ACID.
A CEO's application invariants may include such examples as "For every submitted video, there should either be a transcoded version suitable for mobile devices, or there should be a thread working on transcoding." Or "the clients never observe Bitcoin wallets that show old values, despite failures." Or "the data analytics run should complete within a few hours, tolerate faults, and always produce correct results." As these examples demonstrate, the invariants pertain to what the users see, and they span not only the state kept in the database, but the state and behavior of the application as well.
Here's the main point: the properties of the database matter only to the extent that they are able to support application invariants, to the extent that the database can act as a suitable foundation for these rich application invariants on top.
Of course, systems with weak properties typically cannot support applications that demand strong invariants. For example, if the red boundary does not provide the big P-word known as Performance, and the blue boundary needs to achieve high throughput, well, the app will then have to go get itself a different red layer that can provide the required performance.
There have been countless debates on eventual consistency and what it's good for, whether it is desirable, and so forth. These discussions are tiresome and boring. And sadly, there are some people out there who have developed knee-jerk, previously-pickled and doled-out-at-the-slightest-stimulus kind of ready-made arguments for and against EC in the abstract. This kind of regurgitation misses the point: the action is at the blue boundary, the red stuff is involved solely by proxy.
What is surprising to many people, based on the reaction to my posts on partition-tolerance and partition-obliviousness (original and followup), is that properties at the red boundary that sound incredibly strong do not necessarily translate into similarly strong properties at the blue layer. Something that sounds as fantastic as "partition-tolerance" in a data store can be the very impediment to achieving partition-tolerance in the application. Recall how almost every first-generation data store jettisoned a lot of desirable properties, purportedly in search of availability and partition tolerance (though I suspect they actually jettisoned the C as in CAP partly because it was hard and partly because they were seeking P as in Performance). Despite that tradeoff for partition-tolerance, the people who buy these systems to achieve partition-tolerance at the blue boundary by osmosis from the red might be in for a surprise.
Until recently, the predominant attitude in the database community was that application developers cannot be trusted with data stores with weak properties. And the gold standard in data stores is ACID semantics. In all fairness to the database community, they collectively have many more decades of experience than any single company or developer. Their attitude makes sense because the DB community is driven by a desire to support as many applications as possible, and "C as in ACID" can express the widest range of application-level invariants on top. This is especially true for a tiered web application, where the front end code is transient and needs to use the back-end database for all its long-term storage needs. And further, the DB community has been around long enough to see that applications often have changing needs, where an application that starts out with a narrow mission with a small number of invariants balloons out over time to demand more. Solutions that are barely sufficient at the onset can turn out to be insufficient as software evolves.
But I do not share this view, and have taken quite a bit of flak from my database colleagues as a result. I am not advocating that developers use a "C as in ACID" data store (even though my group built one), or a "C as in CAP" data store (even though my group built one as well -- HyperDex was first C as in CAP, now supports both C's). If someone can get by with an eventually consistent data store, power to them. A good developer will pick the tool that makes sense for her application. There are an infinite number of applications out there and some can operate well with no consistency guarantees. Some demand no fault-tolerance, as I discussed in the entry on when data is worthless. Some will never evolve.
As I have said before, if someone has modest invariants to maintain at the application level, and they don't foresee their application changing much over time, a first-generation NoSQL store may be a perfect match.
In practice, people often forego systems with strong properties in search of performance, the way they have been abandoning RDBMSs for NoSQL. We now have second-generation systems that not only provide stronger guarantees, but also outperform existing NoSQL systems.
At the end of the day, everyone should pick whatever data store best supports the invariants their applications need to maintain. One could pick Riak for its Erlang or its management API or Cassandra for its durability. For all I care, people are even free to pick systems based on things like, say, how much noise they make in trade magazines, how pretty their logos are or how much schwag they give out (hey, even I have a Mongo t-shirt). But I will admit that I feel what the Germans call "fremdschämen" when I encounter cargo-cult engineering, and I will call out well-funded companies that encourage developers to make bad decisions. Part of my passion to write about NoSQL is to make sure that well-meaning engineers make their tech decisions for good reasons.

To recap: the action is at the blue boundary. C as in ACID can support a wide range of application-level consistency properties that can be expressed over the current contents of the database. C as in CAP is useful when the application's invariants do not span more than one object. EC is the weakest possible property (where "weak" here is a value-neutral, technical term) that can cause time to move backwards where objects revert to an older value temporarily, or disappear and reappear; yet, even EC is a perfectly fine choice for applications whose invariants are not violated by such behavior. The main point is that, in the concrete here-and-now, what matters aren't the abstract properties of the red boundary, but what needs to be achieved at the blue boundary.
There are some non-obvious effects, where seemingly good properties of the red boundary (say, partition-tolerance) can transfer themselves onto the blue one as a weak facsimile of themselves (e.g. partition-obliviousness). None of this is deep or even complicated for good engineers, but somehow the field has been characterized by religious arguments over murky definitions.
In an ideal world, this would all be basic, well-established material we cover in undergraduate courses, but many of us have had to pick up this material from disparate sources, which use slightly different definitions for terms. And that has created a lot of confusion. The distinction between properties of the data store (red boundary) and properties of an application (blue boundary) seems to get short shrift, and causes even more confusion. I hope this overview is useful, and I look forward to discussions where all parties are using more or less the same terminology.

Hacker and professor at Cornell, with interests that span distributed systems, OSes and networking. Current projects include HyperDex, OpenReplica and the Nexus OS. more...




bitcoin / security / ethereum / hyperdex / release / nosql / selfish-mining / blocksize / dao / surveillance / privacy / mongo / broken / weaver / nsa / meta / leveldb / blockchain / 51% / voting / smart contracts / graph stores / decentralization / bitcoin-ng / vaults / snowden / satoshi / philosophy / mt. gox / mining pools